Code like song
Benchmarking Temporal Foreign Keys
Way back in Februrary Peter Eisentraut asked me if I’d tested the performance of my patch to add temporal foreign keys to Postgres.
Have you checked that the generated queries can use indexes and have suitable performance? Do you have example execution plans maybe?
Here is a report on the tests I made. I gave a talk about this last month at pdxpug, but this blog post will be easier to access, and I’ll focus just on the foreign key results.
Method
As far as I know there are no published benchmark schemas or workflows for temporal data. Since the tables require start/end columns, you can’t use an existing benchmark like TCP-H. The tables built in to pgbench are no use either. I’m not even sure where to find a public dataset. The closest is something called “Incumben”, mentioned in the “Temporal Alignment” paper. They authors say it has 85,857 entries for job assignments across 49,195 employees at the University of Arizona—but I can’t find any trace of it online. (I’ll update here if I hear back from them about it.)
So I built a temporal benchmark of my own using CMU’s Benchbase framework. (Thanks to Mark Wong and Grant Holly for that recommendation!) It also uses employees and positions, both temporal tables with a valid_at column (a daterange). Each position has a reference to an employee, checked by a temporal foreign key. Primary and foreign keys have GiST indexes combining the integer part and the range part. Here is the DDL:
CREATE TABLE employees (
id int GENERATED BY DEFAULT AS IDENTITY NOT NULL,
valid_at daterange NOT NULL,
name text NOT NULL,
salary int NOT NULL,
PRIMARY KEY (id, valid_at WITHOUT OVERLAPS)
);
CREATE TABLE positions (
id int GENERATED BY DEFAULT AS IDENTITY NOT NULL,
valid_at daterange NOT NULL,
name text NOT NULL,
employee_id int NOT NULL,
PRIMARY KEY (id, valid_at WITHOUT OVERLAPS),
FOREIGN KEY (employee_id, PERIOD valid_at) REFERENCES employees (id, PERIOD valid_at)
);
CREATE INDEX idx_positions_employee_id ON positions USING gist (employee_id, valid_at);Naturally you can’t run that unless you’ve compiled Postgres with the temporal patches above.
The benchmark has procedures that exercise foreign keys (update/delete employee, insert/update position). There are other procedures too: selecting one row, selecting many rows, inner join, outer join, semijoin, antijoin. I plan to add aggregates and set operations (union/except/intersect), as well as better queries for sequenced vs non-sequenced semantics. But right now the foreign key procedures are better developed than anything else. I also plan to change the SQL from rangetypes to standard SQL:2011 PERIODs, at least for non-Postgres RDBMSes. I’ll write more about all that later; this post is about foreign keys.
range_agg Implementation
Temporal foreign keys in Postgres are implemented like this:
SELECT 1
FROM (
SELECT pkperiodatt AS r
FROM [ONLY] pktable x
WHERE pkatt1 = $1 [AND ...]
AND pkperiodatt && $n
FOR KEY SHARE OF x
) x1
HAVING $n <@ range_agg(x1.r)This is very similar to non-temporal checks. The main difference is we use range_agg to aggregate referenced records, since it may require their combination to satisfy the reference. For example if the employee got a raise in the middle of the position, neither employee record alone covers the position’s valid time:
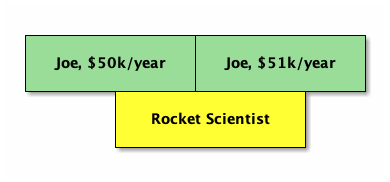
In our query, the HAVING checks that the “sum” of the employee times covers the position time.
A subquery is not logically required, but Postgres currently doesn’t allow FOR KEY SHARE in a query with aggregations.
I like this query because it works not just for rangetypes, but multiranges too. In fact we could easily support arbitrary types, as long as the user provides an opclass with an appropriate support function (similar to the stratnum support function introduced for temporal primary keys). We would call that function in place of range_agg. But how does it perform?
EXISTS implementation
I compared this query with two others. The original implementation for temporal foreign keys appears on pages 128–129 of Developing Time-Oriented Database Applications in SQL by Richard Snodgrass. I call this the “EXISTS implementation”. Here is the SQL I used:
SELECT 1
-- There was a PK when the FK started:
WHERE EXISTS
SELECT 1
FROM [ONLY] <pktable>
WHERE pkatt1 = $1 [AND ...]
AND COALESCE(lower(pkperiodatt), '-Infinity')
<= COALESCE(lower($n), '-Infinity')
AND COALESCE(lower($n), '-Infinity')
< COALESCE(upper(pkperiodatt), 'Infinity')
)
-- There was a PK when the FK ended:
AND EXISTS (
SELECT 1
FROM [ONLY] <pktable>
WHERE pkatt1 = $1 [AND ...]
AND COALESCE(lower(pkperiodatt), '-Infinity')
< COALESCE(upper($n), 'Infinity')
AND COALESCE(upper($n), 'Infinity')
<= COALESCE(upper(pkperiodatt), 'Infinity')
)
-- There are no gaps in the PK:
-- (i.e. there is no PK that ends early,
-- unless a matching PK record starts right away)
AND NOT EXISTS (
SELECT 1
FROM [ONLY] <pktable> AS pk1
WHERE pkatt1 = $1 [AND ...]
AND COALESCE(lower($n), '-Infinity')
< COALESCE(upper(pkperiodatt), 'Infinity')
AND COALESCE(upper(pkperiodatt), 'Infinity')
< COALESCE(upper($n), 'Infinity')
AND NOT EXISTS (
SELECT 1
FROM [ONLY] <pktable> AS pk2
WHERE pk1.pkatt1 = pk2.pkatt1 [AND ...]
-- but skip pk1.pkperiodatt && pk2.pkperiodatt
AND COALESCE(lower(pk2.pkperiodatt), '-Infinity')
<= COALESCE(upper(pk1.pkperiodatt), 'Infinity')
COALESCE(upper(pk1.pkperiodatt), 'Infinity')
< COALESCE(upper(pk2.pkperiodatt), 'Infinity')
)
);The main idea here is that we check three things: (1) the referencing row is covered in the beginning, (2) it is covered in the end, (3) in between, the referenced row(s) have no gaps.
I made a few changes to the original:
- It can’t be a
CHECKconstraint, since it references other rows. - There is less nesting. The original is wrapped in a big
NOT EXISTSand looks for bad rows. Essentially it says “there are no invalid records.” In Postgres we check one referencing row at a time, and we give a result if it is valid. You could say we look for good rows. This also requires inverting the middle-layerEXISTSandNOT EXISTSpredicates, and changingORs toANDs. I’ve often run into trouble withOR, so this is probably fortunate. - We have to “unwrap” the start/end times since they are stored in a rangetype. I could have used rangetype operators here, but I wanted to keep the adaptation as straightforward as possible, and the previous changes felt like a lot already. Unwrapping requires dealing with unbounded ranges, so I’m using plus/minus
Infinityas a sentinel. This is not perfectly accurate, since in ranges a null bound is “further out” than a plus/minusInfinity. (Tryselect '{(,)}'::datemultirange - '{(-Infinity,Infinity)}'::datemultirange.) But again, solving that was taking me too far from the original, and it’s fine for a benchmark. - We need to lock the rows with
FOR KEY SHAREin the same way as above. We need to do this in each branch, since they may use different rows.
Given the complexity, I didn’t expect this query to perform very well.
lag implementation
Finally there is an implementation in Vik Fearing’s periods extension. This is a lot like the EXISTS implementation, except to check for gaps it uses the lag window function. Here is the SQL I tested:
SELECT 1
FROM (
SELECT uk.uk_start_value,
uk.uk_end_value,
NULLIF(LAG(uk.uk_end_value) OVER
(ORDER BY uk.uk_start_value), uk.uk_start_value) AS x
FROM (
SELECT coalesce(lower(x.pkperiodatt), '-Infinity') AS uk_start_value,
coalesce(upper(x.pkperiodatt), 'Infinity') AS uk_end_value
FROM pktable AS x
WHERE pkatt1 = $1 [AND ...]
AND uk.pkperiodatt && $n
FOR KEY SHARE OF x
) AS uk
) AS uk
WHERE uk.uk_start_value < upper($n)
AND uk.uk_end_value >= lower($n)
HAVING MIN(uk.uk_start_value) <= lower($n)
AND MAX(uk.uk_end_value) >= upper($n)
AND array_agg(uk.x) FILTER (WHERE uk.x IS NOT NULL) IS NULLAgain I had to make some adaptations to the original
- There is less nesting, for similar reasons as before.
- We unwrap the ranges, much like the
EXISTSversion. Again there is anInfinity-vs-null discrepancy, but it is harder to deal with since the query uses null entries in thelagresult to indicate gaps. - I couldn’t resist using
&&instead of<=and>=in the most-nested part to find relevant rows. The change was sufficiently obvious, and if it makes a difference it should speed things up, so it makes the comparison a bit more fair.
I made a new branch rooted in my valid-time branch, and added an extra commit to switch between each implementation with a compile-tag flag. By default we still use range_agg, but instead you can say ‑DRI_TEMPORAL_IMPL_LAG or ‑DRI_TEMPORAL_IMPL_EXISTS. I installed each implementation in a separate cluster, listening on port 5460, 5461, and 5462 respectively.
I also included procedures in Benchbase to simply run the above queries as SELECTs. Since we are doing quite focused microbenchmarking here, I thought that would be less noisy than doing the same DML for each implementation. It also means we can run a mix of all three implementations together: they use the same cluster, and if there is any noise on the machine it affects them all. If you look at my temporal benchmark code, you’ll see the same SQL but adapted for the employees/positions tables.
Hypothesis
Here is the query plan for the range_agg implementation:
Aggregate
Filter: ('[2020-10-10,2020-12-12)'::daterange <@ range_agg(x1.r))
-> Subquery Scan on x1
-> LockRows
-> Index Scan using employees_pkey on employees x
Index Cond: ((id = 500) AND (valid_at && '[2020-10-10,2020-12-12)'::daterange))It uses the index, and it all seems like what we’d want. It is not an Index Only Scan, but that’s because we lock the rows. Non-temporal foreign keys are the same way. This should perform pretty well.
Here is the query plan for the EXISTS implementation:
Result
One-Time Filter: ((InitPlan 1).col1 AND (InitPlan 2).col1 AND (NOT (InitPlan 4).col1))
InitPlan 1
-> LockRows
-> Index Scan using employees_pkey on employees x
Index Cond: ((id = 500) AND (valid_at && '[2020-10-10,2020-12-12)'::daterange))
Filter: ((COALESCE(lower(valid_at), '-infinity'::date) <= '2020-10-10'::date) AND ('2020-10-10'::date < COALESCE(upper(valid_at), 'infinity'::date)))
InitPlan 2
-> LockRows
-> Index Scan using employees_pkey on employees x_1
Index Cond: ((id = 500) AND (valid_at && '[2020-10-10,2020-12-12)'::daterange))
Filter: ((COALESCE(lower(valid_at), '-infinity'::date) < '2020-12-12'::date) AND ('2020-12-12'::date <= COALESCE(upper(valid_at), 'infinity'::date)))
InitPlan 4
-> LockRows
-> Index Scan using employees_pkey on employees pk1
Index Cond: ((id = 500) AND (valid_at && '[2020-10-10,2020-12-12)'::daterange))
Filter: (('2020-10-10'::date < COALESCE(upper(valid_at), 'infinity'::date)) AND (COALESCE(upper(valid_at), 'infinity'::date) < '2020-12-12'::date) AND (NOT EXISTS(SubPlan 3)))
SubPlan 3
-> LockRows
-> Index Scan using employees_pkey on employees pk2
Index Cond: (id = pk1.id)
Filter: ((COALESCE(lower(valid_at), '-infinity'::date) <= COALESCE(upper(pk1.valid_at), 'infinity'::date)) AND (COALESCE(upper(pk1.valid_at), 'infinity'::date) < COALESCE(upper(valid_at), 'infinity'::date)))That looks like a lot of work!
And here is the plan for the lag implementation:
Aggregate
Filter: ((array_agg(uk.x) FILTER (WHERE (uk.x IS NOT NULL)) IS NULL) AND (min(uk.uk_start_value) <= '2020-10-10'::date) AND (max(uk.uk_end_value) >= '2020-12-12'::date))
-> Subquery Scan on uk
Filter: ((uk.uk_start_value < '2020-12-12'::date) AND (uk.uk_end_value >= '2020-10-10'::date))
-> WindowAgg
-> Sort
Sort Key: uk_1.uk_start_value
-> Subquery Scan on uk_1
-> LockRows
-> Index Scan using employees_pkey on employees x
Index Cond: ((id = 500) AND (valid_at && '[2020-10-10,2020-12-12)'::daterange))This looks a lot like the range_agg version. We still use our index. There is an extra Sort step, but internally the range_agg function must do much the same thing (if not something worse). Maybe the biggest difference (though a slight one) is aggregating twice.
So I expect range_agg to perform the best, with lag a close second, and EXISTS far behind.
One exception may be a single referencing row that spans many referenced rows. If range_agg is O(n2), it should fall behind as the referenced rows increase.
Results
I started by running a quick test on my laptop, an M2 Macbook Air with 16 GB of RAM. I tested the DML commands on each cluster, one after another. Then I checked the benchbase summary file for the throughput. The results were what I expected:
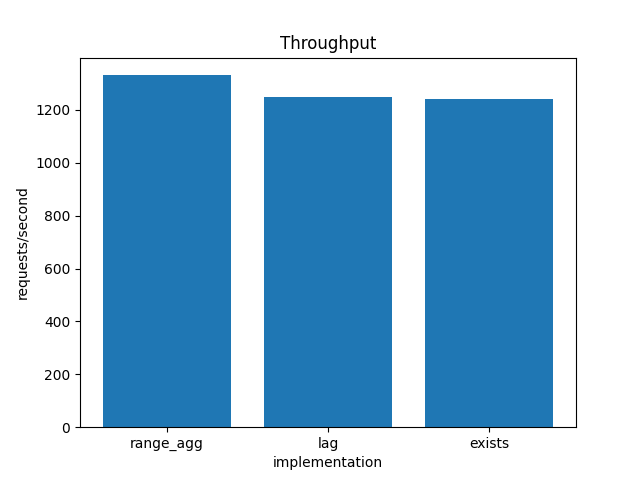
Similarly, range_agg had the best latency at the 25th, 50th, 75th, 90th, and 99th percentiles:
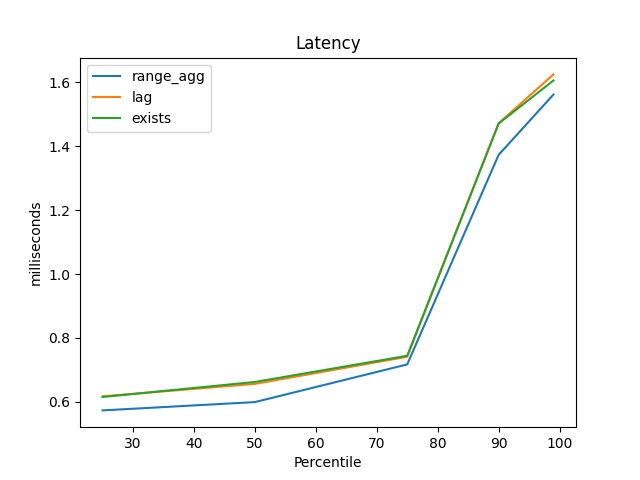
But the difference throughout is pretty small, and at the time my Benchbase procedures used a lot of synchronized blocks to ensure there were few foreign key failures, and that kind of locking seemed like it might throw off the results. I needed to do more than this casual check.
I ran all the future benchmarks on my personal desktop, running Ubuntu 22.04.
It was hard to make things reproducible, but I wrote various scripts as I went, and I tried to capture results. The repo for all that is here. My pdxpug talk above contains some reflections about improving my benchmark methodology.
I also removed the synchronized blocks and dealt with foreign key failures a better way (by categorizing them as errors but not raising an exception).
The first more careful tests used the direct SELECT statements.
Again, the 95th percentile latency was what I expected:
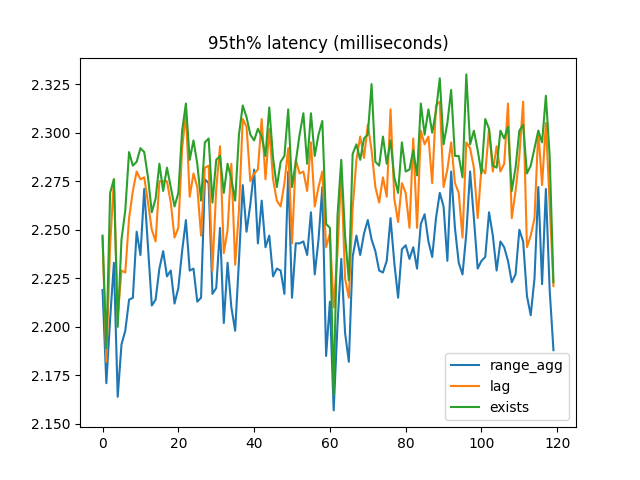
But the winner for mean latency was EXISTS!:
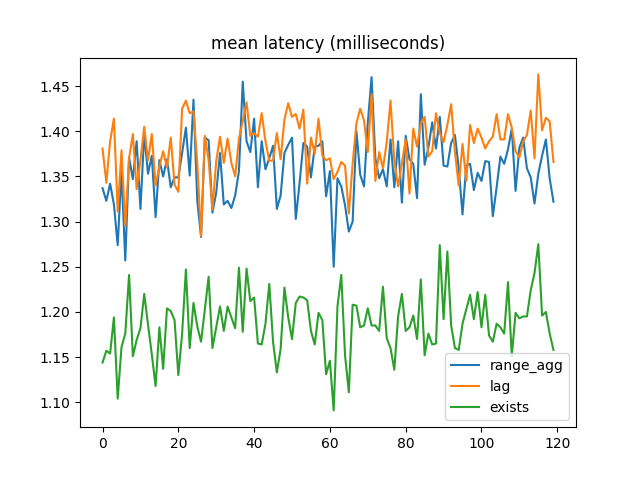
A clue was in the Benchbase output showing successful transactions vs errors. (The Noop procedure is so can make the proportions 33/33/33/1 instead of 33/33/34.):
Completed Transactions:
com.oltpbenchmark.benchmarks.temporal.procedures.CheckForeignKeyRangeAgg/01 [72064] ********************************************************************************
com.oltpbenchmark.benchmarks.temporal.procedures.CheckForeignKeyLag/02 [71479] *******************************************************************************
com.oltpbenchmark.benchmarks.temporal.procedures.CheckForeignKeyExists/03 [71529] *******************************************************************************
com.oltpbenchmark.benchmarks.temporal.procedures.Noop/04 [ 4585] *****
Aborted Transactions:
<EMPTY>
Rejected Transactions (Server Retry):
<EMPTY>
Rejected Transactions (Retry Different):
<EMPTY>
Unexpected SQL Errors:
com.oltpbenchmark.benchmarks.temporal.procedures.CheckForeignKeyRangeAgg/01 [80861] ********************************************************************************
com.oltpbenchmark.benchmarks.temporal.procedures.CheckForeignKeyLag/02 [80764] *******************************************************************************
com.oltpbenchmark.benchmarks.temporal.procedures.CheckForeignKeyExists/03 [80478] *******************************************************************************More than half of the transactions were an invalid reference.
And if we put one of those into EXPLAIN ANALYZE, we see that most of the plan was never executed:
Result (actual time=0.034..0.035 rows=0 loops=1)
One-Time Filter: ((InitPlan 1).col1 AND (InitPlan 2).col1 AND (NOT (InitPlan 4).col1))
InitPlan 1
-> LockRows (actual time=0.033..0.033 rows=0 loops=1)
-> Index Scan using employees_pkey on employees x (actual time=0.033..0.033 rows=0 loops=1)
Index Cond: ((id = 5999) AND (valid_at && '[2020-10-10,2020-12-12)'::daterange))
Filter: ((COALESCE(lower(valid_at), '-infinity'::date) <= '2020-10-10'::date) AND ('2020-10-10'::date < COALESCE(upper(valid_at), 'infinity'::date)))
InitPlan 2
-> LockRows (never executed)
-> Index Scan using employees_pkey on employees x_1 (never executed)
Index Cond: ((id = 5999) AND (valid_at && '[2020-10-10,2020-12-12)'::daterange))
Filter: ((COALESCE(lower(valid_at), '-infinity'::date) < '2020-12-12'::date) AND ('2020-12-12'::date <= COALESCE(upper(valid_at), 'infinity'::date)))
InitPlan 4
-> LockRows (never executed)
-> Index Scan using employees_pkey on employees pk1 (never executed)
Index Cond: ((id = 5999) AND (valid_at && '[2020-10-10,2020-12-12)'::daterange))
Filter: (('2020-10-10'::date < COALESCE(upper(valid_at), 'infinity'::date)) AND (COALESCE(upper(valid_at), 'infinity'::date) < '2020-12-12'::date) AND (NOT EXISTS(SubPlan 3)))
SubPlan 3
-> LockRows (never executed)
-> Index Scan using employees_pkey on employees pk2 (never executed)
Index Cond: (id = pk1.id)
Filter: ((COALESCE(lower(valid_at), '-infinity'::date) <= COALESCE(upper(pk1.valid_at), 'infinity'::date)) AND (COALESCE(upper(pk1.valid_at), 'infinity'::date) < COALESCE(upper(valid_at), 'infinity'::date)))In this example, the beginning of the referencing range wasn’t covered, so Postgres never had to check the rest. Essentially the query is a AND b AND c, so Postgres can short-circuit the evaluation as soon as it finds a to be false. Using range_agg or lag doesn’t allow this, because an aggregate/window function has to run to completion to get a result.
As confirmation (a bit gratuitous to be honest), I ran the EXISTS benchmark with this bpftrace script:
// Count how many exec nodes per query were required,
// and print a histogram of how often each count happens.
// Run this for each FK implementation separately.
// My hypothesis is that the EXISTS implementation calls ExecProcNode far fewer times,
// but only if the FK is invalid.
u:/home/paul/local/bench-*/bin/postgres:standard_ExecutorStart {
@nodes[tid] = 0
}
u:/home/paul/local/bench-*/bin/postgres:ExecProcNode {
@nodes[tid] += 1
}
u:/home/paul/local/bench-*/bin/postgres:standard_ExecutorEnd {
@calls = hist(@nodes[tid]);
delete(@nodes[tid]);
}For EXISTS I got this histogram when there were no invalid references:
@calls:
[0] 6 | |
[1] 0 | |
[2, 4) 0 | |
[4, 8) 228851 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[8, 16) 1 | |
[16, 32) 1 | |
[32, 64) 2 | |
[64, 128) 2 | |
[128, 256) 2 | |
[256, 512) 5 | |But with 50%+ errors I got this:
@calls:
[0] 6 | |
[1] 0 | |
[2, 4) 218294 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[4, 8) 183438 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[8, 16) 231 | |
[16, 32) 1 | |
[32, 64) 2 | |
[64, 128) 2 | |
[128, 256) 2 | |
[256, 512) 5 | |So more than half the time, Postgres ran the query with half the steps (maybe one-fourth).
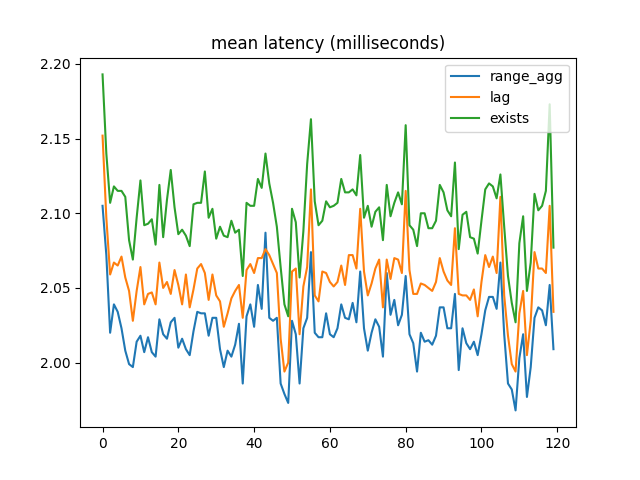
After tuning the random numbers to bring errors closer to 1%, I got results more like the original ones. Mean latency:
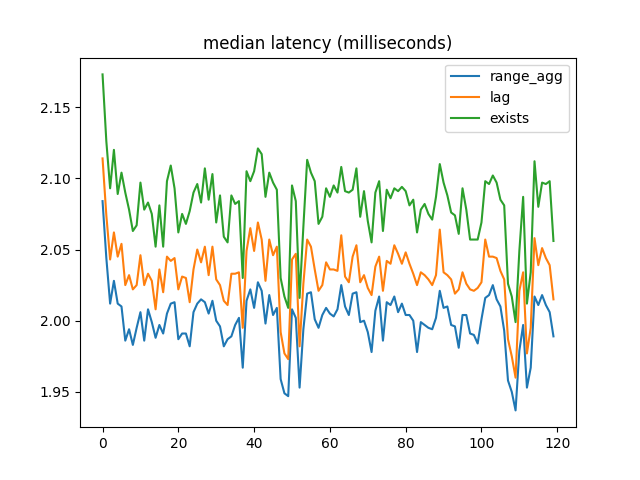
Median latency:
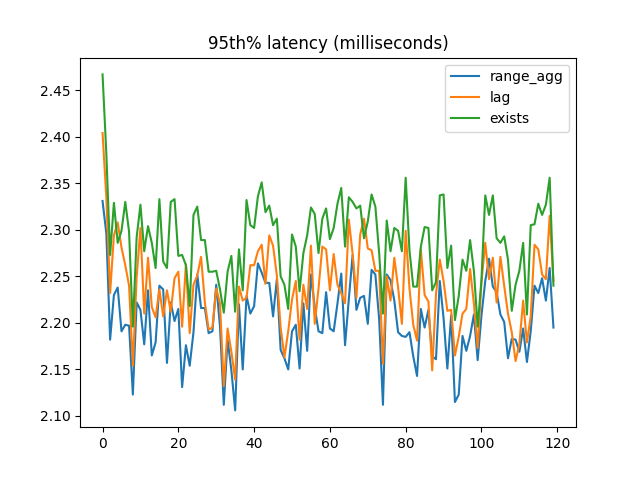
95th percentile latency:
Conclusions
All foreign key implementations have expected query plans. We use indexes where we should, etc.
When most foreign key references are valid, range_agg outperforms the other two implementations by a small but consistent amount. But with a large number of invalid references, EXISTS is a lot faster.
In most applications I’ve seen, foreign keys are used as guardrails, and we expect 99% of checks to pass (or more really). When using ON DELETE CASCADE the situation is different, but these benchmarks are for NO ACTION or RESTRICT, and I don’t think CASCADE affords the EXISTS implementation the same shortcuts. So it seems right to optimize for the mostly-valid case, not the more-than-half-invalid case.
These results are good news, because range_agg is also more general: it supports multiranges and custom types.
Further Work
There are more things I’d like to benchmark (and if I do I’ll update this post):
- Replace separate start/end comparisons with range operators in the
EXISTSandlagimplementations. I just need to make sure they still pass all the tests when I do that. - Correct the
Infinity-vs-null discrepancy. - Monitor the CPU and disk activity under each implementation and compare the results. I don’t think I’ll see any difference in disk, but CPU might be interesting.
- Compare different scale factors (i.e. starting number of employees/positions).
- Compare implementations when an employee is chopped into many small records, and a single position spans all of them. If
range_aggis O(n2) that should be worse than the sorting in the other options. - Compare temporal foreign keys to non-temporal foreign keys (based on B-tree indexes, not GiST). I’m not sure yet how to do this in a meaningful way. Of course b-trees are faster in general, but how do I use them to achieve the same primary key and foreign key constraints? Maybe the best way is to create the tables without constraints, give them only b-tree indexes, and run the direct
SELECTstatements, not the DML.


Code

Writing

Talks

- Temporal Benchmark
- Inlining Postgres Functions
- Temporal Databases 2024
- Papers We Love: Temporal Alignment
- Benchbase for Postgres Temporal Foreign Keys
- Hacking Postgres: the Exec Phase
- Progress Adding SQL:2011 Valid Time to Postgres
- Temporal Databases: Theory and Postgres
- A Rails Timezone Strategy
- Rails and SQL
- Async Programming in iOS
- Errors in Node.js
- Wharton Web Intro
- PennApps jQuery Intro