Code like song
Basics of Web Architecture
2014-03-07
by Paul A. Jungwirth re
web
This post is adapted from an email I wrote several years ago and have since reused many times to help explain the “moving pieces” on the web to non-programmers. Someone on Hacker News asked about this kind of thing, so I thought I’d finally post it, with some images reused from my old talk at Wharton about the same thing. This article won’t make you a programmer, but hopefully it can give a big-picture overview of how the major parts fit together. It’s like Web 101. In some places it oversimplifies (lies a little as I like to put it), but in ways that I think are helpful for a beginner.
HTML
HTML hit the world in 1994. The way it works is your web browser, based on a URL, asks a web server somewhere out on the Internet for an HTML file, and the web server sends it back. So there are two actors: the web browser and the web server.
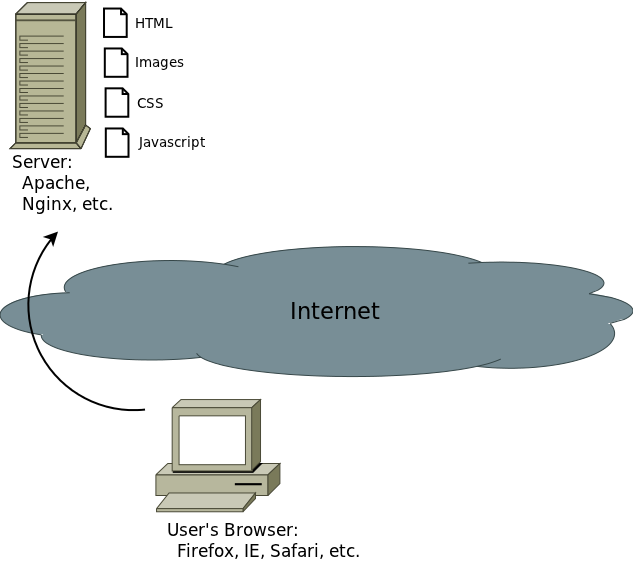
The web server is just a program running on someone else’s computer. The most popular web server is called Apache, but there are many others. A web server listens for people requesting URLs, and it sends back HTML files, images, etc. There are lots of companies out there that will host your website for you. Basically they provide a web server, and you upload whatever files you want the world to see.
The web browser is Firefox or Safari or IE or whatever. You type a URL into the address bar, and it finds the web server out on the Internet and asks it for the file in the URL. The server sends it some HTML, and the browser is responsible for rendering the HTML file. It may also request supporting files like images. Different web browsers render HTML slightly differently, making many headaches for web designers.

HTML stands for HyperText Markup Language. The HyperText means it has links you can click to visit new pages, and the Markup means you use angle-bracket tags to “mark up” certain parts of the text. In markup, there is an opening tag and (usually) a closing tag. The closing tag repeats the name of the opening tag, but with a forward slash at the beginning. This markup can indicate structure or display. For instance, <i>ibid</i> will render “ibid” in italics; this is an example of using markup for display. On the other hand, you might have this:
<ul>
<li>Walk the dog</li>
<li>Do the laundry</li>
<li>Pay the bills</li>
</ul>This produces a bulleted list with three items (ul = unnumbered list, li = list item):
- Walk the dog.
- Do the laundry.
- Pay the bills.
A tag may also have attributes, which look like name="value". This is how you write links, which are “anchor tags”: <a href="http://www.google.com/">Click here to visit Google</a>.
HTML may reference other files. When this happens, the browser downloads those files too and adds them to the display. The main example is images, which work like this: <img src="my-portrait.png">. (Notice there is no closing tag for images.) And here are some other cases of HTML referencing outside files:
CSS
CSS stands for Cascading StyleSheets. It’s an attempt to separate out display-style information from the HTML code, so the HTML just contains structural markup. A CSS file is a separate file, referenced by the HTML file, which tells how each type of element should be rendered (e.g. in big font, with a 2-pixel red border, or whatever). It’s considered good form to use CSS for display and HTML for structure, at least insofar as that’s possible. This is partly because it reduces typing and makes changes easier, it makes reading the HTML easier, and you can have different people working on different things. CSS also supports more advanced display options that just HTML, so some effects you can only achieve with CSS.
Again, each browser interprets CSS in its own slightly incompatible way. People who write really slick-looking web pages spend a ton of time discovering and applying tricks to get an acceptable display on each browser type. One way is to write separate HTML+CSS files for each browser type, detect what a user is using, and send the appropriate files. But no one really does this. At most people write a special CSS file for IE (which is the most incompatible with the others), and then use special codes to serve it only to IE browsers. There are other less drastic techniques as well.
Because this gets so expensive, it’s common to decide up front which browsers you’ll support, and which will get a slightly wonky-looking site. Your choice will depend on your expected audience. Nowadays some sites will just refuse to support older browsers or even not-so-old versions of IE. I like to aim for IE 8+ or even 7+. If you’re somebody like Amazon, then you add browsers with less market share like IE 5+, Safari, Opera, Konquerer, and maybe more. (Amazon is perhaps a bad example because most of their site uses a fairly loose, flexible design, so slight inconsistencies aren’t noticeable. A better example would be something with an artsy look like a winery.) Nowadays a big new challenge is supporting mobile devices like Androids and iPhones.
Javascript
Javascript is a full-fledged programming language (unlike HTML & CSS), with sequential execution of commands, variables, functions, etc. It runs on the user’s browser, which means a web server sends a bunch of Javascript code over the Internet, and the user runs it on his local machine. You can put Javascript straight into an HTML page like this:
<script language="javascript">
alert("Hello World!");
</script>Or you can have a separate .js file referenced by the HTML page.
Either way, the point of Javascript is to cause dynamic effects in the user’s browser. You can’t accomplish this with HTML or CSS, because those just tell how to lay out the page. With Javascript you can make things change and move around. You can add popups like “Do you really want to delete that?” or “Call today for your free sample!”
Note that Javascript has nothing to do with Java. It was invented by Netscape when Java was a hip new programming language (invented by Sun), and as a marketing gimmick they called it Javascript. Really!
Again, different browsers treat Javascript in different ways. This is where the browser incompatibilities are the worst. It can be truly maddening, and to get good results you really need someone with a lot of experience.
jQuery
jQuery is an extension to Javascript. It’s pretty new, but it’s wonderful. It lets you easily get lots of trendy effects like fade-in or rollovers that used to be more expensive to build. It also encapsulates a lot of the cross-browser boilerplate people used to write themselves to support all the different browsers out there. Basically instead of calling native Javascript functions, you call the jQuery functions, which automatically test for the browser’s functionality and do the right thing based on the result. That sort of library has been around for many years, but jQuery is an exceptionally good implementation of it, and it’s quickly become the de facto standard. jQuery makes it much less expensive to get a pretty site and fancy effects.
In fact nowadays (2014) jQuery is old hat! People are doing more and more with Javascript. It’s no longer about rollovers and popups, but many people build their whole interface with Javascript. To manage this extra complexity, there are new frameworks out there like Backbone.js, Angular.js, and Ember.js. These frameworks provide lots of common functionality and help you keep things organized.
Flash
Like Javascript, this is a programming language that gets run browser-side. But whereas Javascript can touch any element on the page, a Flash program is confined to a given square. Flash is particularly aimed at graphics, so the big ads are all written in Flash, and there are lots of Flash games, and YouTube videos are Flash. Unlike with Javascript, Flash doesn’t suffer from cross-browser incompatibilities because it is owned by Adobe (originally by Macromedia), who distributes browser “plugins” that execute the Flash code. Because the browser doesn’t run the Flash directly, it can’t be inconsistent about it. This is why you need a plugin to run Flash.
The are several disadvantages to Flash: It requires users to download the plugin (although most have it already), it is opaque to search engines, so Google can’t index what you put in Flash, and it is unsupported on iPhones. Sometimes it is used to create an intro movie on the front page of sites, but many people find that annoying, so I don’t recommend it. In general, Flash is being replaced with Javascript+HTML5, so learning it may not be a good investment, unless you want to make games or dynamic advertisements.
PHP
Let’s go back to the beginning: the way the web works is your web browser asks a web server for an HTML file, and the web server sends the file across the Internet. But what if the web page is something like a shopping cart, where the HTML is different for each user? In this case, the web server doesn’t just have a static HTML file, but it runs a program to generate an HTML file on the spot, and it sends the result to your web browser. So here the web server is basically a middle-man: it delegates the task of generating the HTML to a separate program, and it passes the result along to the web browser. The old term for this is CGI, and while it isn’t always correct any more to call this sort of thing a CGI, it’s still useful as a catch-all term for any server-side HTML generation. You can build a CGI in whatever language you like. Java and C# are common choices, as is PHP. Most modern techniques, PHP included, involve writing a file that is mostly HTML, with some special code embedded inside to output the variable parts. Generally people choose PHP for smaller sites and Java/C#/Python/Ruby for bigger sites, but that distinction seems less valid each year.
CGI (in any language) is quite different from browser-side programming like Javascript and Flash. First of all, it all happens on your own web server, so you don’t have to deal with browser incompatibilities. CGI is invisible to the user. By the time the browser sees anything, it’s just got plain old HTML. On the other hand, this means that CGI can’t give you effects like animations and popups, which require executing code on the browser. CGI is just a way to serve different HTML to each user. Note that CGI is not incompatible with Javascript and Flash. Any website of moderate complexity will employ CGI on the server side to generate custom HTML, plus Javascript/Flash on the browser side to get flashy effects. (You can even use CGI to dynamically generate Javascript, CSS, or images, but this is rare.)
Using CGI also imposes a larger burden on your web server than just serving static HTML files. Maybe the CGI has to access a database to find a user’s favorite genre of books, for example. If you have a lot of traffic, it’s important to consider the efficiency of your CGI code. The ability to support lots of traffic is called scalability. This isn’t something you really ought not worry about too much right away, but someone experienced will make fewer mistakes here.
An aside about performance
On the web, “performance” has two components: latency and scalability. Latency is how snappy your site is: how quickly you can serve a page and get all the images etc. loaded. Big players like Google and Facebook have done studies showing that engagement and conversions drop off if you have page load times over 600ms or so, hence the saying “speed is a feature.”
Scalability, on the other hand, refers to how well your site degrades as you add more users. So instead of snappiness, it’s about capacity. You can also think of scalability as how hard/expensive it is to add more capacity.
People talk about “vertical” vs. “horizontal” scalability. Vertical scalability means buying faster hardware. Horizontal scalability means buying more cheap hardware and distributing the load. Vertical scalability is expensive and has hard limits, but horizontal scalability requires careful up-front design. Rails and Django are nice frameworks because they enable or even in some ways force a more scalable architecture. One thing that is hard (by “hard” I mean it’s a current research topic for Ph.D.s) is horizontal scaling for databases. There are worthwhile techniques, but they are complex to implement. Often it’s better to just buy a bigger box.
Latency and scalability don’t always come together. You can be snappy but crash when a media hit causes traffic to spike, or you could have a sluggish site that keeps chugging no matter how many visitors arrive. Sometimes optimizations will help both categories, but not always.
Java+J2EE, Ruby+Rails, Python+Django
These are all server-side technologies like PHP. But you have to distinguish between the programming language and the web application framework. Like PHP, Java, Ruby, and Python are all programming languages. You can do anything with them. Each language also has a leading framework that helps you build web sites, so that you aren’t starting from scratch. These frameworks are J2EE, Ruby on Rails, and Django. So Ruby and Rails are two different things. Rails is open source code written in Ruby that implements things needed by every web site. You then add your custom Ruby code that uses Rails to do its job.
J2EE, Rails, and Django all go beyond CGI in that they are “application servers”, so they do more work for you, like tracking sessions and pooling database connections. (Actually PHP can do that, too.) They encourage a pattern of web development called Model-View-Controller (MVC), which helps separate your code into different concerns. The Model defines the structure of your data and your “business logic.” It is the back end of your site. Its job is to talk to the database and provide a convenient, intelligible API for the other layers. The Controller is what handles incoming web requests. Each request goes to the Controller code first. The Controller decides what to do. It asks things like “Is this person logged in?” and “What page do I show for this URL?” The View is what renders the actual HTML. Usually you write your view in some kind of templating mini-language, like JSP or ERB or HAML. All those languages let you write a bunch of HTML and then embed Java/Ruby/etc code into it to inject things like user names, product images, or whatever. In general, the Controller sets up whatever data the View will need by loading Model objects, and then the View reads those Model objects to fill in its blanks.
To new coders, MVC probably seems like a lot of extraneous infrastructure. It does increase the learning curve, but it’s basically the standard in professional web development. It’s the pattern adopted by J2EE, Rails, and Django as the right way to build websites. By separating your code into layers and giving each layer its own responsibility, it becomes much easier to manage complexity. Otherwise it’s all but impossible to reason correctly about what your code will do. Without MVC, it’s easy to make a small change and inadvertently break something that you thought was unrelated. MVC protects you from this kind of thing. It also makes it easier to separate tasks among multiple developers.
blog comments powered by Disqus Prev: Dates and Time Zones in Rails Next: Why not distribute public keys via SMTP?

Code

Writing

Talks

- Migrating to a Temporal Schema
- Temporal Roadmap
- Temporal Benchmark
- Inlining Postgres Functions
- Temporal Databases 2024
- Papers We Love: Temporal Alignment
- Benchbase for Postgres Temporal Foreign Keys
- Hacking Postgres: the Exec Phase
- Progress Adding SQL:2011 Valid Time to Postgres
- Temporal Databases: Theory and Postgres
- A Rails Timezone Strategy
- Rails and SQL
- Async Programming in iOS
- Errors in Node.js
- Wharton Web Intro
- PennApps jQuery Intro